IA
L’intelligence artificielle repose sur l’idée
que les fonctions cognitives, en particulier l’apprentissage, le raisonnement, le calcul,
la perception, la mémorisation, voire la
découverte scientifique ou la créativité artistique,
peuvent être reproduites sur des ordinateurs.
La capacité d’apprentissage est une caractéristique fréquemment attribuée à l’intelligence et la notion s’est très vite retrouvée au centre des recherches en intelligence artificielle.
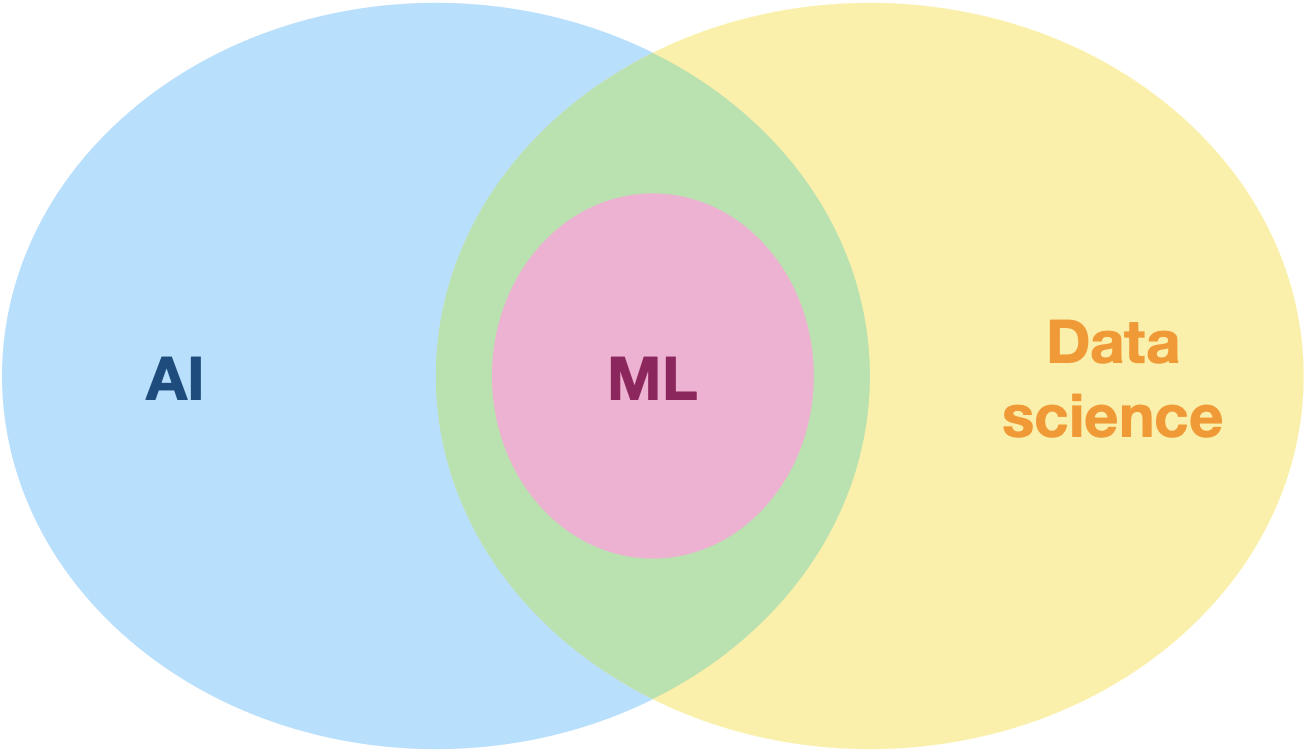
L’apprentissage automatique (Machine Learning) est un champ d’étude de l’intelligence artificielle qui vise à donner aux machines la capacité d’apprendre à partir de données,
via des modèles mathématiques.
L’apprentissage automatique est à l’intersection de l’IA et de la science des données (data science).
Il ya 3 types d’apprentissage automatique en fonction du type d’interaction avec les données :
- l'apprentissage supervisé : on fournit à l'algorithme des données étiquetées et il doit apprendre à étiqueter de nouvelles données.
- l'apprentissage non supervisé : on fournit à l'algorithme des données sans étiquette et il doit apprendre à les ranger en catégories.
- l'apprentissage par renforcement : l'algorithme interagit avec son environnement qui le récompense ou le punit.
Exemple d’apprentissage supervisé :
Algorithme des K
plus proches voisins (kNN)
Comment, à partir de données fournies,
un programme peut-il apprendre à prédire
la catégorie d’une nouvelle donnée
qu’il n’a jamais vue ?
Dans l’animation suivante, on montre comment KNN parvient à répondre à la question suivante :
Quelle est la couleur du nouveau point ?
Le choix de $k$ modifie le résultat obtenu.
Que se passe-t-il si $k$ est trop petit ?
On moyenne sur très peu de points
et donc la variabilité est très grande.
On parle alors de surapprentissage (overfitting).
Et si $k$ est trop grand ?
L'algorithme finit par choisir systématiquement
la catégorie majoritaire, quel que soit
le nouveau point...
On augmente alors le biais (ici, le biais est
le préjudice en faveur du plus grand nombre)
et l'ajustement ne suit plus les variations.
On parle de sous-apprentissage (underfitting).
Le choix de $k$ est donc affaire de compromis.
Pour le rendre plus scientifique, on peut chercher
à mesurer la performance de l’algorithme
pour différentes valeurs de $k$.
Mais comment mesurer sa performance ?
Un tableau de contingence va nous permettre d’évaluer la qualité des prédictions de l’algorithme.
Utilisons KNN sur une banque d’images
de chiffres écrits à la main.
Données d’apprentissage :
1797 images de 8 par 8 pixels (en fait une liste de 64 nombres entre 0 et 255) extraits de la base de données MNIST et leurs étiquettes (le chiffre écrit).
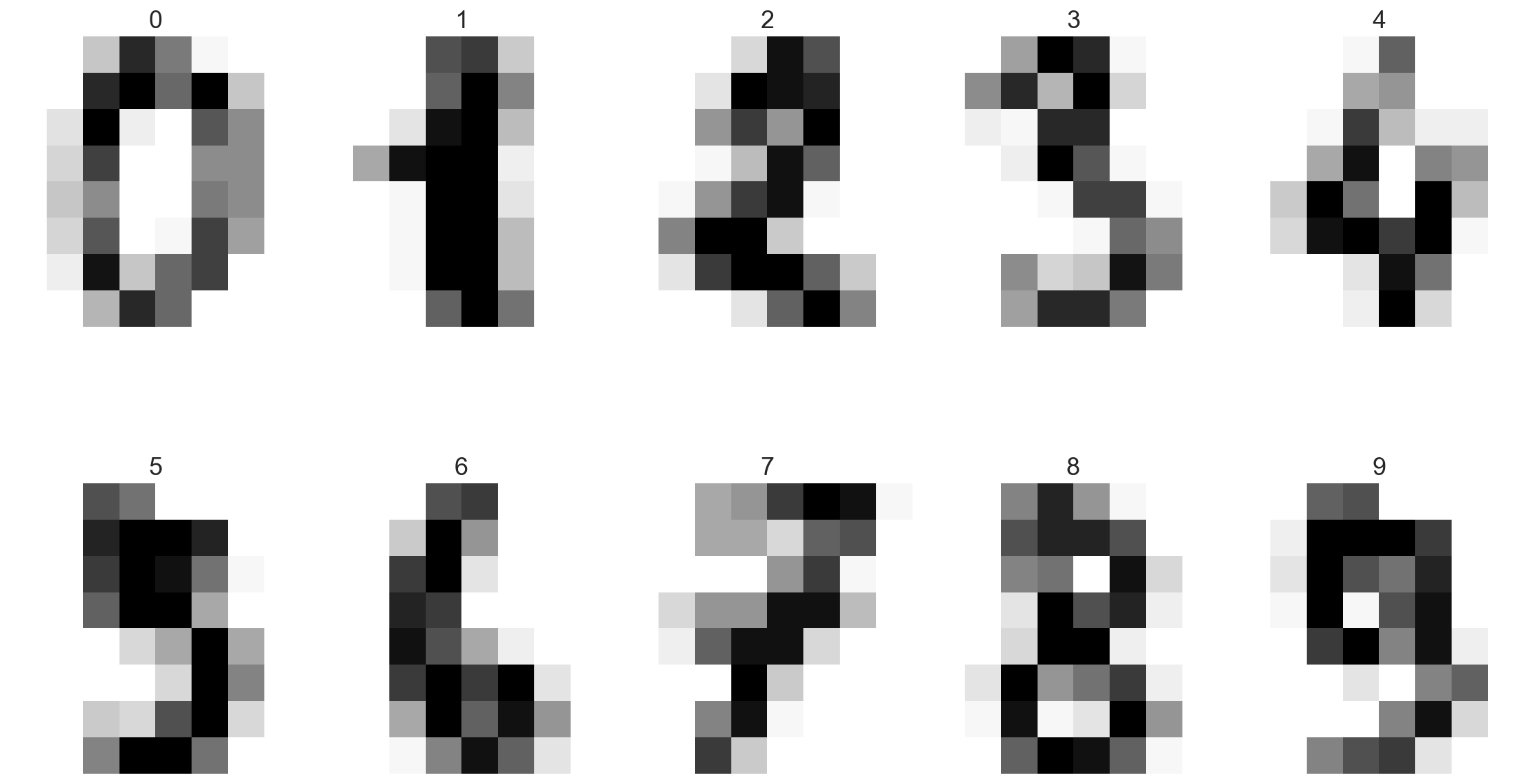
Code Python du programme :
def dist(x,Pts):
n = len(x)
L = []
for pt in Pts:
d = 0
for i in range(n):
d += (pt[i]-x[i])**2
d = d**0.5
L.append(d)
return L
import statistics as stat
def KNN(X,k,Appr,Etiq):
L = dist(X,Appr)
LplusEtiq = []
for i in range(len(L)):
LplusEtiq.append((L[i],Etiq[i]))
LplusEtiq.sort()
EtiqFin = []
for e in LplusEtiq[:k]:
EtiqFin.append(e[1])
return stat.mode(EtiqFin)
Prédiction:
Concentrons-nous sur sa capacité à reconnaître des “3” pour dresser le tableau de contingence (aussi appelé matrice de confusion).
précision $\displaystyle =\frac{\mathrm{VP}}{\mathrm{VP+FP}}$
sensibilité $\displaystyle =\frac{\mathrm{VP}}{\mathrm{VP+FN}}$
exactitude $\displaystyle =\frac{\mathrm{VP+VN}}{\mathrm{VP+VN+FP+FN}}$
Un algorithme peut très bien être très précis
(les prédictions positives sont bien des 3),
mais peu sensible (parmi tous les 3,
peu ont été identifiés).
À l’inverse, on peut avoir une bonne sensibilité
(la plupart des vrais 3 ont été identifiés comme tel), mais peu précis (beaucoup de chiffres identifiés comme des 3 sont en fait d’autres chiffres).
L’algorithme kNN est très utilisé
dans l’industrie, dans des domaines variés :
des recommandations sur les sites d’e-commerce jusqu’à l’aide au diagnostique médical sur
des images de radio ou d’IRM.
Rq :
il peut être préféré à des solutions plus modernes dans des secteurs réglementés comme la santé
ou la finance car il est facilement interprétable
(on comprend ce qu’il fait).
Exemple d’apprentissage non-supervisé :
Algorithme des
K-moyennes
La tâche d’un algorithme d’apprentissage
non-supervisé est de dévoiler les
structures cachées des données..
L’algorithme des k-moyennes regroupe
en catégories des données dont
on ne connaît rien a priori.
C'est un algorithme
de partitionnement
des données (clustering).
L’algorithme dépend d’un seul
paramètre (en plus des données) :
le nombre de partitions k.
- On commence par choisir $k$ points au hasard dans l'espace des données (il peut s'agir de $k$ points de données ou de $k$ autres points).
Ce sont les $k$ centres (ou centroïdes). - On attribue ensuite à chaque centre tous les points de données qui lui sont le plus proches, formant ainsi $k$ groupes.
- Enfin, on déplace chaque centre au barycentre de son groupe.
On répète les deux dernières opérations (attribution des points les plus près
et déplacement des centres)
tant que les centres bougent
d’une itération à l’autre.
L’algorithme vise à résoudre au final un problème d’optimisation ; son but est en effet de trouver
le minimum de la distance entre les points
à l’intérieur de chaque partition.
k-moyenne permet de compresser des images
en regroupant les pixels en k couleurs.

Limites
L’algorithme des k-moyennes est lui aussi
très utilisé dans l’industrie :
- regroupement des clients selon leurs comportements
- optimisation logistique (position d'un dépôt )
- segmentation d'images médicales ou satellites
- création de playlists recommandées (clustering de morceaux)
Apprentissage par renforcement
Cette méthode est très utilisée :
- en robotique (bras articulés, voitures autonomes, etc.)
- pour l'optimisation de procédés industriels (industrie chimique, raffineries, etc.)
- en logistique (planification des tâches)
- pour la gestion intelligente des réseaux électriques (smart grid)
Apprentissage profond
(deep learning)
Révolutionne le secteur de l’IA
dans les années 2010.
Il consiste à entraîner un ordinateur à “apprendre” en analysant un grand nombre d’exemples à l’aide de structures mathématiques appelées réseaux
de neurones, qui s’inspirent vaguement
du fonctionnement du cerveau humain.
L’idée de “profondeur” vient du fait que les réseaux de neurones utilisés dans le deep learning
ont de nombreuses couches.
Chaque couche effectue une partie de l’analyse
et transmet ses résultats à la suivante.
C’est un peu comme si un problème complexe était résolu par une série d’étapes simples, chacune
se concentrant sur un détail particulier.
Superbes présentations des réseaux
de neurones par 3Blue1Brown
Le principal problème du deep learning :
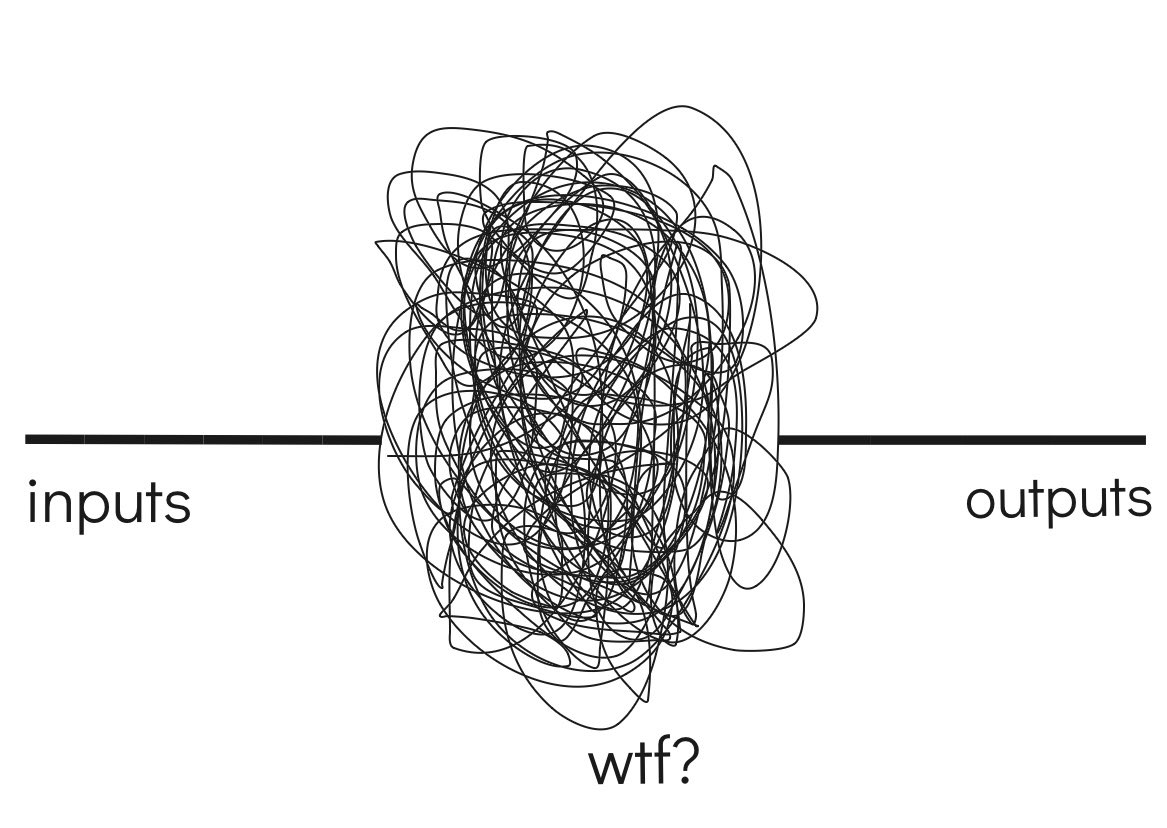
Ça marche, mais on ne sait pas bien comment.
La cuisine interne du réseau de neurone dans
ses couches cachées est mystérieuse…
On parle de boîte noire.
Grands modèles
de langage
(LLM)
Toute la phase d’apprentissage du langage correspond à de l’apprentissage supervisé.
Puis on ajoute une couche d’apprentissage par renforcement (supervisé par des humains ou d’autres IA) pour rendre le modèle “docile”.
Essayer de comprendre comment les LLM “pensent” (interprétabilité) et à quoi ils pensent vraiment (sécurité) devient de plus en plus crucial au fur et à mesure que notre dépendance grandit.
Exemple d’avancée en interprétabilité :
des chercheurs d'Anthropic ont réussi à isoler des concepts dans le "cerveau" de Claude qu'ils
ont pu ensuite amplifier ou inhiber.
C'est comme ça qu'on a pu interagir pendant
une journée avec Golden Gate Claude...
Problèmes
que posent l’IA
SLOP
Envahissement d'internet et des réseaux sociaux par des contenus de basse qualité générés par IA (slop) qui noient les contenus humains de qualité.
Sur un million de pages générées par l'IA
sur un sujet, il n'est pas rare qu'une finisse propulsée en tête des recherches par
l'algorithme de Google...
Des biais pourrissent
les données
Biais du survivant
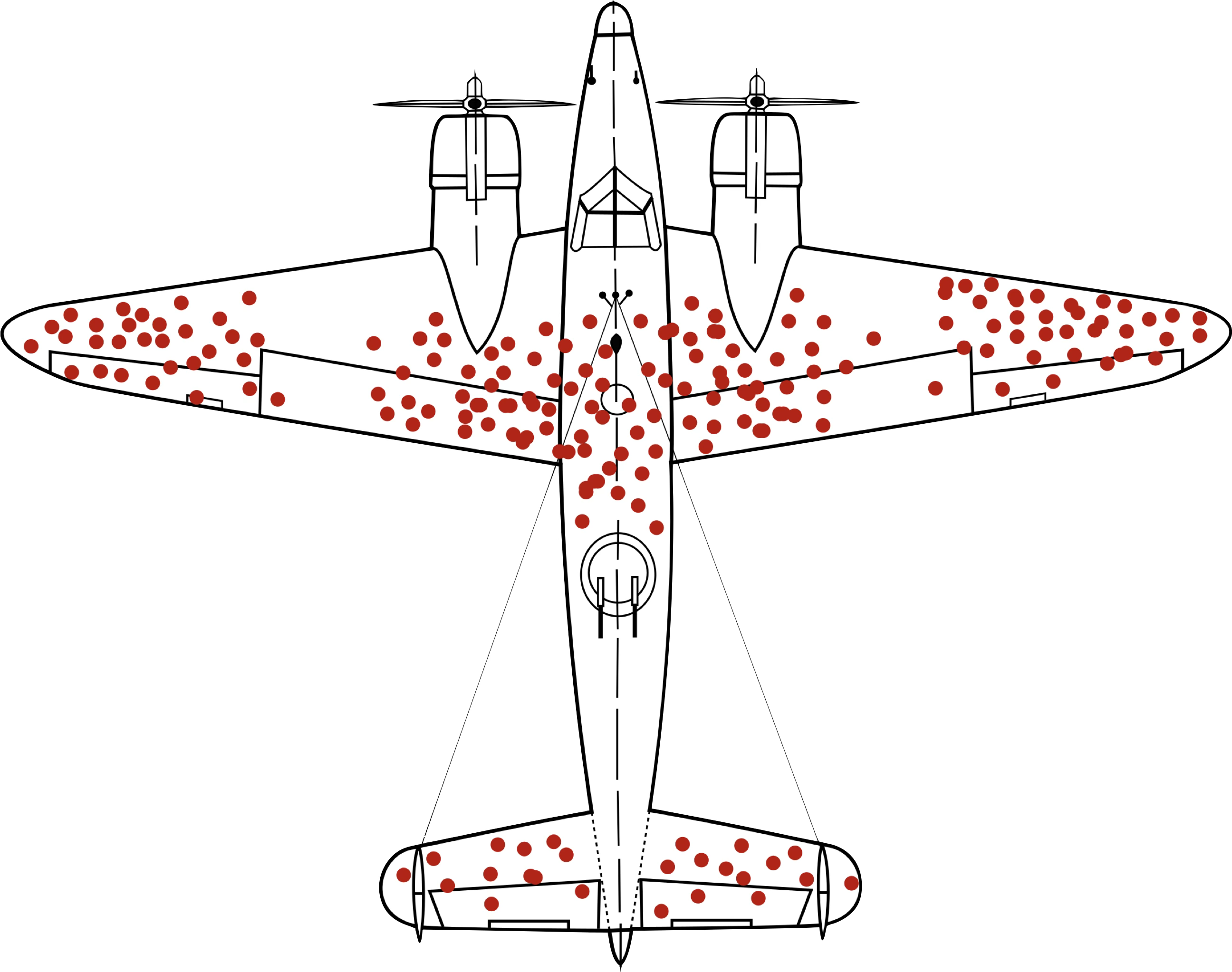
C’est lui qui nous fait penser
que tout était mieux avant.
Dans le cas d'une IA, on lui apprend à imiter ce
qui marche… sans comprendre ce qui échoue.
Le biais des survivants est un exemple
de biais de sélection.

L’entraînement des IA, en particulier celui des IA génératives, est très sensible à ces défauts de représentation de la même façon qu’un enfant élevé dans un milieu particulier (secte par exemple) aura beaucoup de mal à se faire une représentation adaptée du reste du monde.
Pour les LLM, un surentraînement
vise à gommer ces biais.
Mais tant que les LLM n'auront pas une représentation fiable des relations de causalités, des biais pourront persister.
Corrélation ≠ causalité
Confondre corrélation et causalité revient à penser que les pompiers causent les incendies puisqu'on les trouve toujours là où ça brûle.
Ou encore que les ventes de glaces causent
les attaques de requins puisque les deux
sont fortement corrélées.
Ce chouette site recense pleins
de corrélations amusantes.
Les IA sont excellentes pour trouver des corrélations (ce sont avant tout des machines statistiques) mais très mauvaises pour comprendre la causalité car leur apprentissage ne suppose jusqu’ici aucune interaction avec
leur environnement.
Et couplé avec le biais de sélection, les IA génératives peuvent reproduire des
stéréotypes sexistes ou racistes.
Exemple :
Si les données d’apprentissage contiennent plus d’infirmiers ou secrétaires femmes et de patrons ou ingénieurs hommes, le modèle pourra en déduire que le métier d’ingénieur est trop difficile pour une femme alors que le métier
de secrétaire leur est plus adapté.
Là encore, le surapprentissage vise à gommer
ces représentations erronées.
Pour le coup, les humains
ne sont pas un bon modèle…
Beaucoup de monde peine en effet
à comprendre la situation suivante :
A father and his son driving together in their car have a terrible car accident. The father dies upon impact. The son is rushed to the hospital in an ambulance and is immediately brought to the operating table. The doctor takes a quick look at him and says that a specialist is needed.
The specialist comes, looks at the young man on the operating table and proclaims, I cannot operate on him, he is my son.
Dilemmes moraux
Dans une situation où vous sacrifier permet de sauver plusieurs vies, la voiture autonome qui
vous conduit doit-elle choisir de vous tuer ?
Le MIT a mené une expérience sociologique
à grande échelle sur ces questions.
Problème de l’alignement
On se rend compte au fur et à mesure que les LLM savent mentir, dissimuler, tromper, manipuler, tricher lorsqu'ils se savent évalués, feindre
de partager certaines valeurs...
Dans son livre Superintelligence, le philosophe
Nick Bostrom explique que quel que soit l’objectif initial d’une IA largement supérieure à l’intelligence humaine (une superintelligence), l’éradication
de l’humanité peut se présenter
comme un effet secondaire.

Pour illustrer cette idée, il utilise son célèbre exemple d’une IA dont le but est de maximiser
la production de trombones.

Même un objectif comme
“faire en sorte que chaque humain soit heureux” peut s’avérer très problématique…
Pourquoi ?